
This is the memo of the 3rd course (5 courses in all) of ‘Statistics Fundamentals with Python’ skill track.
You can find the original course HERE .
### Table of contents
#### Reasons for Modeling: Interpolation
One common use of modeling is
interpolation
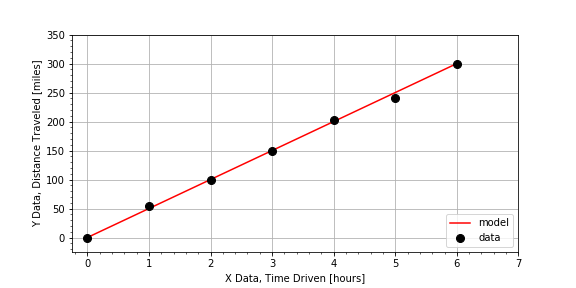
to determine a value “inside” or “in between” the measured data points. In this exercise, you will make a prediction for the value of the dependent variable
distances
for a given independent variable
times
that falls “in between” two measurements from a road trip, where the distances are those traveled for the given elapse times.
times, distances
[hours], [miles]
0.0, 0.00
1.0, 44.05
2.0, 107.16
3.0, 148.44
4.0, 196.40
5.0, 254.44
6.0, 300.00
# Compute the total change in distance and change in time
total_distance = distances[-1] - distances[0]
total_time = times[-1] - times[0]
# Estimate the slope of the data from the ratio of the changes
average_speed = total_distance / total_time
# Predict the distance traveled for a time not measured
elapse_time = 2.5
distance_traveled = average_speed * elapse_time
print("The distance traveled is {}".format(distance_traveled))
# The distance traveled is 125.0
Notice that the answer distance is ‘inside’ that range of data values, so, less than the max(distances) but greater than the min(distances) .
#### Reasons for Modeling: Extrapolation
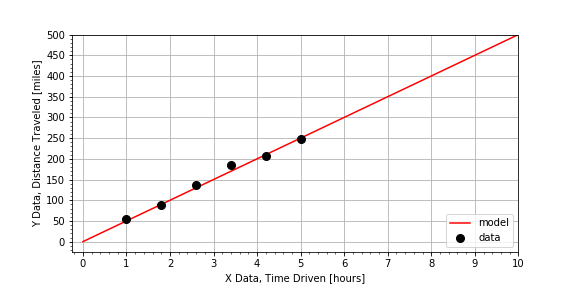
Another common use of modeling is
extrapolation
to estimate data values
“outside”
or
“beyond”
the range (min and max values of
time
) of the measured data. In this exercise, we have measured distances for times 0 through 5 hours, but we are interested in estimating how far we’d go in 8 hours. Using the same data set from the previous exercise, we have prepared a linear model
distance = model(time)
. Use that
model()
to make a prediction about the distance traveled for a time much larger than the other times in the measurements.
# Select a time not measured.
time = 8
# Use the model to compute a predicted distance for that time.
distance = model(time)
# Inspect the value of the predicted distance traveled.
print(distance)
# Determine if you will make it without refueling.
answer = (distance <= 400)
print(answer)
Notice that the car can travel just to the range limit of 400 miles, so you’d run out of gas just as you completed the trip
#### Reasons for Modeling: Estimating Relationships
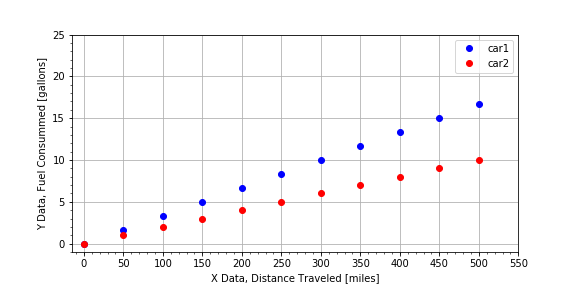
Another common application of modeling is to
compare two data sets
by building models for each, and then
comparing the models
. In this exercise, you are given data for a road trip two cars took together. The cars stopped for gas every 50 miles, but each car did not need to fill up the same amount, because the cars do not have the same fuel efficiency (MPG). Complete the function
efficiency_model(miles, gallons)
to estimate efficiency as average miles traveled per gallons of fuel consumed. Use the provided dictionaries
car1
and
car2
, which both have keys
car['miles']
and
car['gallons']
.
car1
{'gallons': array([ 0.03333333, 1.69666667, 3.36 , 5.02333333,
6.68666667, 8.35 , 10.01333333, 11.67666667,
13.34 , 15.00333333, 16.66666667]),
'miles': array([ 1. , 50.9, 100.8, 150.7, 200.6, 250.5, 300.4, 350.3,
400.2, 450.1, 500. ])}
# Complete the function to model the efficiency.
def efficiency_model(miles, gallons):
return np.mean( miles / gallons )
# Use the function to estimate the efficiency for each car.
car1['mpg'] = efficiency_model(car1['miles'] , car1['gallons'] )
car2['mpg'] = efficiency_model(car2['miles'] , car2['gallons'] )
# Finish the logic statement to compare the car efficiencies.
if car1['mpg'] > car2['mpg'] :
print('car1 is the best')
elif car1['mpg'] < car2['mpg'] :
print('car2 is the best')
else:
print('the cars have the same efficiency')
# car2 is the best
Notice the original plot that visualized the raw data was plot gpm(), and the slope is 1/MPG and so car1 is steeper than car2, but if you call plot mpg(gallons, miles) the slope is MPG, and so car2 has a steeper slope than car1
#### Plotting the Data
Everything in python is an object, even modules. Your goal in this exercise is to review the use of the object oriented interfaces to the python library
matplotlib
in order to visualize measured data in a more flexible and extendable work flow. The general plotting work flow looks like this:
import matplotlib.pyplot as plt
fig, axis = plt.subplots()
axis.plot(x, y, color="green", linestyle="--", marker="s")
plt.show()
# Create figure and axis objects using subplots()
fig, axis = plt.subplots()
# Plot line using the axis.plot() method
line = axis.plot(times , distances , linestyle=" ", marker="o", color="red")
# Use the plt.show() method to display the figure
plt.show()

Notice how linestyle=’ ‘ means no line at all, just markers.
#### Plotting the Model on the Data
Continuing with the same measured data from the previous exercise, your goal is to use a predefined
model()
and measured data
times
and
measured_distances
to compute modeled distances, and then plot both measured and modeled data on the same axis.
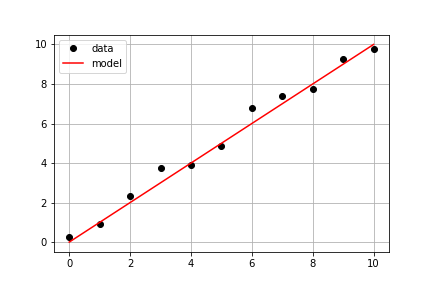
# Pass times and measured distances into model
model_distances = model(times, measured_distances)
# Create figure and axis objects and call axis.plot() twice to plot data and model distances versus times
fig, axis = plt.subplots()
axis.plot(times, measured_distances, linestyle=" ", marker="o", color="black", label="Measured")
axis.plot(times, model_distances, linestyle="-", marker=None, color="red", label="Modeled")
# Add grid lines and a legend to your plot, and then show to display
axis.grid(True)
axis.legend(loc="best")
plt.show()

Notice a subtlety of python.
None
is a special object that is often used as a place-holder to be replaced by default values, so
linestyle=None
does not mean no line, it means the default which is a solid line style, whereas
marker=None
triggers the default marker, which happens to be no marker at all. If you use
color=None
, the resulting color will be blue, the default line color for
matplotlib
.
#### Visually Estimating the Slope & Intercept
Building linear models is an automated way of doing something we can roughly do “manually” with data visualization and a lot of trial-and-error. The visual method is not the most efficient or precise method, but it does illustrate the concepts very well, so let’s try it!
Given some measured data, your goal is to guess values for slope and intercept, pass them into the model, and adjust your guess until the resulting model fits the data. Use the provided data
xd, yd
, and the provided function
model()
to create model predictions. Compare the predictions and data using the provided
plot_data_and_model()
.
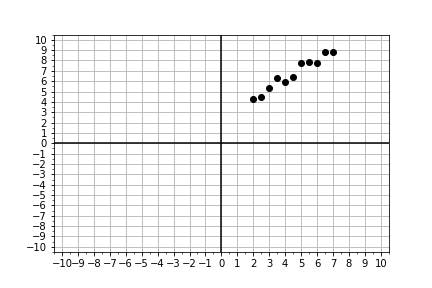
# Look at the plot data and guess initial trial values
trial_slope = 1.2
trial_intercept = 1.8
# input thoses guesses into the model function to compute the model values.
xm, ym = model(trial_intercept, trial_slope)
# Compare your your model to the data with the plot function
fig = plot_data_and_model(xd, yd, xm, ym)
plt.show()
# Repeat the steps above until your slope and intercept guess makes the model line up with the data.
final_slope = 1.2
final_intercept = 1.8

Notice that you did not have to get the best values,
slope = 1
and
intercept = 2
, just something close. Models almost NEVER match the data exactly, and a model created from slightly different model parameters might fit the data equally well. We’ll cover quantifying model performance and comparison in more detail later in this course!
#### Mean, Deviation, & Standard Deviation
The mean describes the center of the data. The standard deviation describes the spread of the data. But to compare two variables, it is convenient to normalize both. In this exercise, you are provided with two arrays of data, which are highly correlated, and you will compute and visualize the normalized deviations of each array.
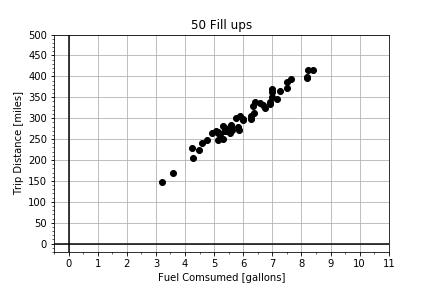
# Compute the deviations by subtracting the mean offset
dx = x - np.mean(x)
dy = y - np.mean(y)
# Normalize the data by dividing the deviations by the standard deviation
zx = dx / np.std(x)
zy = dy / np.std(y)
# Plot comparisons of the raw data and the normalized data
fig = plot_cdfs(dx, dy, zx, zy)

Notice how hard it is to compare dx and dy, versus comparing the normalized zx and zy.
#### Covariance vs Correlation
Covariance is a measure of whether two variables change (“vary”) together. It is calculated by computing the products, point-by-point, of the deviations seen in the previous exercise,
dx[n]*dy[n]
, and then finding the average of all those products.
Correlation is in essence the normalized covariance. In this exercise, you are provided with two arrays of data, which are highly correlated, and you will visualize and compute
both
the
covariance
and the
correlation
.
# Compute the covariance from the deviations.
dx = x - np.mean(x)
dy = y - np.mean(y)
covariance = np.mean(dx * dy)
print("Covariance: ", covariance)
# Covariance: 69.6798182602
# Compute the correlation from the normalized deviations.
zx = dx / np.std(x)
zy = dy / np.std(y)
correlation = np.mean(zx * zy)
print("Correlation: ", correlation)
# Plot the normalized deviations for visual inspection.
fig = plot_normalized_deviations(zx, zy)
# Correlation: 0.982433369757

Notice that you’ve plotted the product of the normalized deviations, and labeled the plot with the correlation, a single value that is the mean of that product. The product is always positive and the mean is typical of how the two vary together.
#### Correlation Strength
Intuitively, we can look at the plots provided and “see” whether the two variables seem to “vary together”.
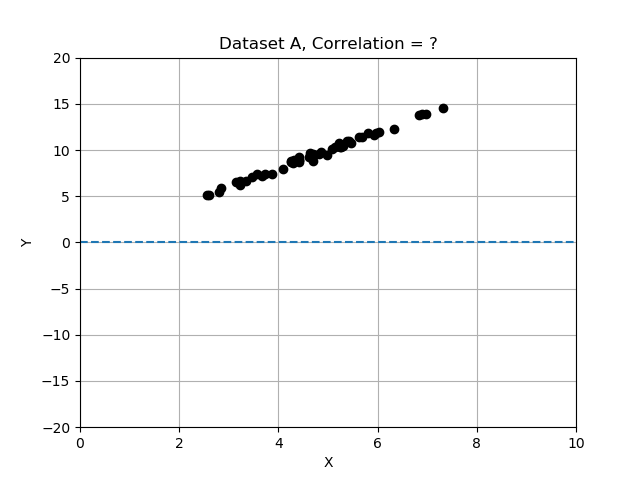
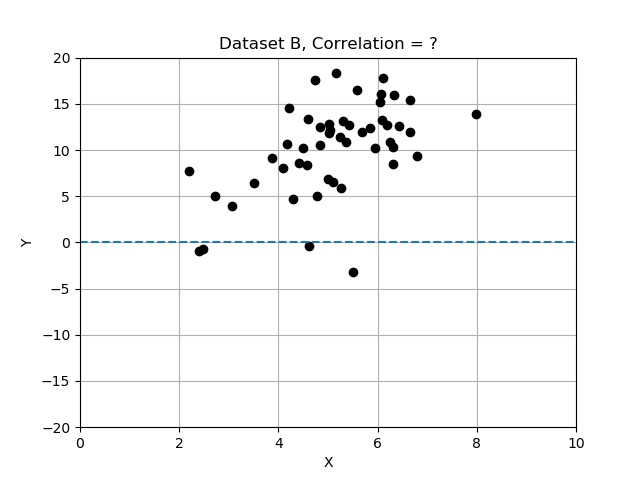
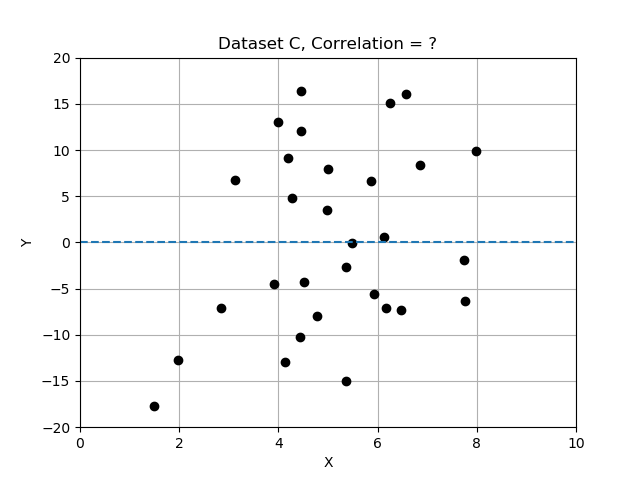
Recall that deviations differ from the mean, and we normalized by dividing the deviations by standard deviation. In this exercise you will compare the 3 data sets by computing correlation, and determining which data set has the most strongly correlated variables x and y. Use the provided data table
data_sets
, a dictionary of records, each having keys ‘name’, ‘x’, ‘y’, and ‘correlation’.
# Complete the function that will compute correlation.
def correlation(x,y):
x_dev = x - np.mean(x)
y_dev = y - np.mean(y)
x_norm = x_dev / np.std(x)
y_norm = y_dev / np.std(y)
return np.mean(x_norm * y_norm)
# Compute and store the correlation for each data set in the list.
for name, data in data_sets.items():
data['correlation'] = correlation(data['x'], data['y'])
print('data set {} has correlation {:.2f}'.format(name, data['correlation']))
# Assign the data set with the best correlation.
best_data = data_sets['A']
# data set A has correlation 1.00
# data set B has correlation 0.54
# data set C has correlation 0.09
Note that the strongest relationship is in Dataset A, with correlation closest to 1.0 and the weakest is Datatset C with correlation value closest to zero.



#### Model Components
In this exercise, you will implement a model function that returns model values for
y
, computed from input
x
data, and any input coefficients for the “zero-th” order term
a0
, the “first-order” term
a1
, and a quadratic term
a2
of a model (see below).
y=a0+a1x+a2x2y=a0+a1x+a2x^2
Recall that “first order” is linear, so we’ll set the defaults for this general linear model with
a2=0
, but later, we will change this for comparison.
# Define the general model as a function
def model(x, a0=3, a1=2, a2=0):
return a0 + (a1*x) + (a2*x**2)
# Generate array x, then predict y values for specific, non-default a0 and a1
x = np.linspace(-10, 10, 21)
y = model(x)
# Plot the results, y versus x
fig = plot_prediction(x, y)

Notice that we used
model()
to compute predicted values of
y
for given possibly measured values of
x
. The model takes the independent data and uses it to generate a model for the dependent variables corresponding values.
#### Model Parameters
Now that you’ve built a
general
model, let’s “optimize” or “fit” it to a new (preloaded) measured data set,
xd, yd
, by finding the
specific
values for model parameters
a0, a1
for which the model data and the measured data line up on a plot.
This is an iterative visualization strategy, where we start with a
guess
for model parameters, pass them into the
model()
, over-plot the resulting modeled data on the measured data, and visually check that the line passes through the points. If it doesn’t, we change the model parameters and try again.
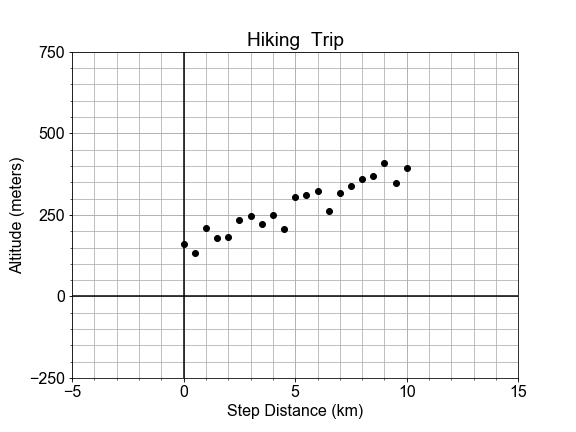
# Complete the plotting function definition
def plot_data_with_model(xd, yd, ym):
fig = plot_data(xd, yd) # plot measured data
fig.axes[0].plot(xd, ym, color='red') # over-plot modeled data
plt.show()
return fig
# Select new model parameters a0, a1, and generate modeled `ym` from them.
a0 = 150
a1 = 25
ym = model(xd, a0, a1)
# Plot the resulting model to see whether it fits the data
fig = plot_data_with_model(xd, yd, ym)

Notice again that the measured x-axis data
xd
is used to generate the modeled y-axis data
ym
so to plot the model, you are plotting
ym
vs
xd
, which may seem counter-intuitive at first. But we are modeling the y response to a given x; we are not modeling x.
#### Linear Proportionality
The definition of temperature scales is related to the linear expansion of certain liquids, such as mercury and alcohol. Originally, these scales were literally rulers for measuring length of fluid in the narrow marked or “graduated” tube as a proxy for temperature. The alcohol starts in a bulb, and then expands linearly into the tube, in response to increasing temperature of the bulb or whatever surrounds it.
In this exercise, we will explore the conversion between the Fahrenheit and Celsius temperature scales as a demonstration of interpreting slope and intercept of a linear relationship within a physical context.
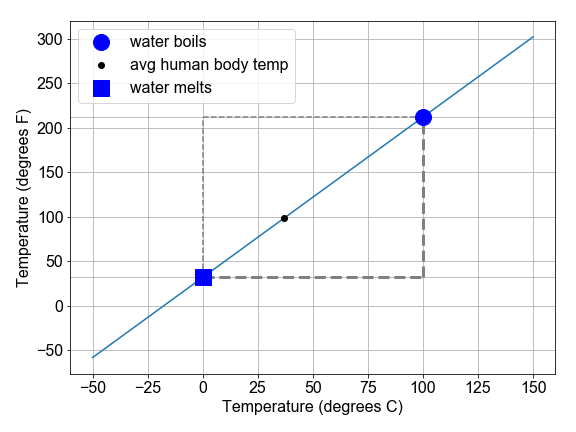
# Complete the function to convert C to F
def convert_scale(temps_C):
(freeze_C, boil_C) = (0, 100)
(freeze_F, boil_F) = (32, 212)
change_in_C = boil_C - freeze_C
change_in_F = boil_F - freeze_F
slope = change_in_F / change_in_C
intercept = freeze_F - freeze_C
temps_F = intercept + (slope * temps_C)
return temps_F
# Use the convert function to compute values of F and plot them
temps_C = np.linspace(0, 100, 101)
temps_F = convert_scale(temps_C)
fig = plot_temperatures(temps_C, temps_F)

#### Slope and Rates-of-Change
In this exercise, you will model the motion of a car driving (roughly) constant velocity by computing the average velocity over the entire trip. The linear relationship modeled is between the time elapsed and the distance traveled.
In this case, the model parameter
a1
, or slope, is approximated or “estimated”, as the mean velocity, or put another way, the “rate-of-change” of the distance (“rise”) divided by the time (“run”).
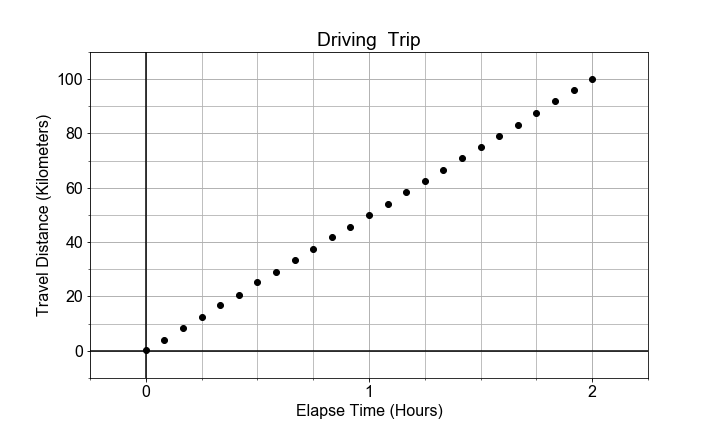
# Compute an array of velocities as the slope between each point
diff_distances = np.diff(distances)
diff_times = np.diff(times)
velocities = diff_distances / diff_times
# Chracterize the center and spread of the velocities
v_avg = np.mean(velocities)
v_max = np.max(velocities)
v_min = np.min(velocities)
v_range = v_max - v_min
# Plot the distribution of velocities
fig = plot_velocity_timeseries(times[1:], velocities)

Generally we might use the average velocity as the slope in our model. But notice that there is some random variation in the instantaneous velocity values when plotted as a time series. The range of values
v_max - v_min
is one measure of the scale of that variation, and the standard deviation of velocity values is another measure. We see the implications of this variation in a model parameter in the next chapter of this course when discussing inference.
#### Intercept and Starting Points
In this exercise, you will see the intercept and slope parameters in the context of modeling measurements taken of the volume of a solution contained in a large glass jug. The solution is composed of water, grains, sugars, and yeast. The total mass of both the solution and the glass container was also recorded, but the empty container mass was not noted.
Your job is to use the preloaded pandas DataFrame
df
, with data columns
volumes
and
masses
, to build a linear model that relates the
masses
(y-data) to the
volumes
(x-data). The slope will be an estimate of the density (change in mass / change in volume) of the solution, and the intercept will be an estimate of the empty container weight (mass when volume=0).
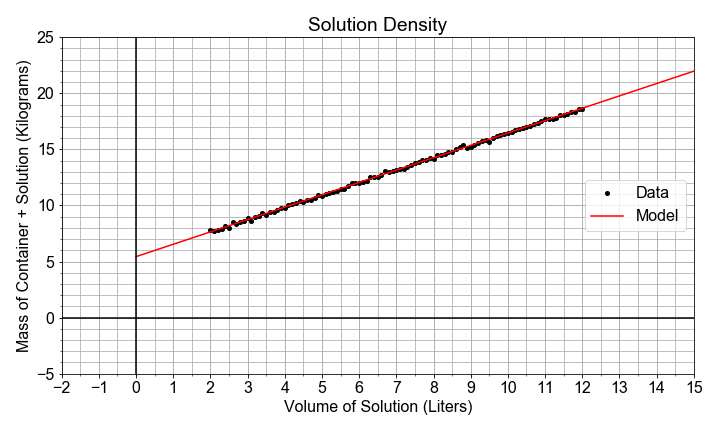
# Import ols from statsmodels, and fit a model to the data
from statsmodels.formula.api import ols
model_fit = ols(formula="masses ~ volumes", data=df)
model_fit = model_fit.fit()
# Extract the model parameter values, and assign them to a0, a1
a0 = model_fit.params['Intercept']
a1 = model_fit.params['volumes']
# Print model parameter values with meaningful names, and compare to summary()
print( "container_mass = {:0.4f}".format(a0) )
print( "solution_density = {:0.4f}".format(a1) )
print( model_fit.summary() )
# container_mass = 5.4349
# solution_density = 1.1029
OLS Regression Results
==============================================================================
Dep. Variable: masses R-squared: 0.999
Model: OLS Adj. R-squared: 0.999
Method: Least Squares F-statistic: 1.328e+05
Date: Wed, 25 Sep 2019 Prob (F-statistic): 1.19e-156
Time: 00:29:26 Log-Likelihood: 102.39
No. Observations: 101 AIC: -200.8
Df Residuals: 99 BIC: -195.5
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 5.4349 0.023 236.805 0.000 5.389 5.480
volumes 1.1029 0.003 364.408 0.000 1.097 1.109
==============================================================================
Omnibus: 0.319 Durbin-Watson: 2.072
Prob(Omnibus): 0.852 Jarque-Bera (JB): 0.169
Skew: 0.100 Prob(JB): 0.919
Kurtosis: 3.019 Cond. No. 20.0
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Don’t worry about everything in the summary output at first glance. We’ll see more of it later. For now, it’s good enough to try to find the slope and intercept values.
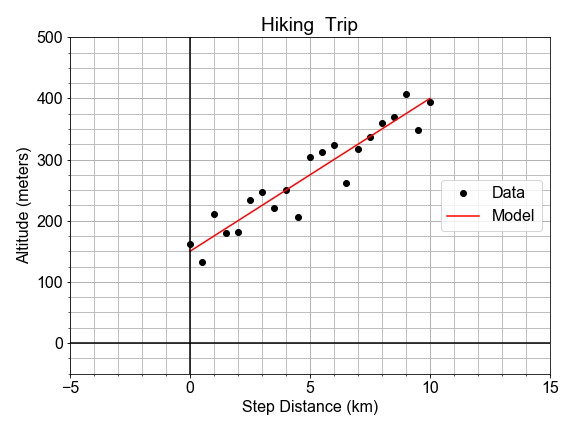
#### Residual Sum of the Squares
In a previous exercise, we saw that the altitude along a hiking trail was roughly fit by a linear model, and we introduced the concept of differences between the model and the data as a measure of model goodness .
In this exercise, you’ll work with the same measured data, and quantifying how well a model fits it by computing the sum of the square of the “differences”, also called “residuals”.
# Load the data
x_data, y_data = load_data()
# Model the data with specified values for parameters a0, a1
y_model = model(x_data, a0=150, a1=25)
# Compute the RSS value for this parameterization of the model
rss = np.sum(np.square(y_data - y_model))
print("RSS = {}".format(rss))
# RSS = 14444.484117694472
The value we compute for RSS is not meaningful by itself, but later it becomes meaningful in context when we compare it to other values of RSS computed for other parameterizations of the model. More on that next!
Some notes about code style; notice you could have done the RSS calculation in a single line of python code, but writing functions than can be re-used is good practice. Notice also that we could have defined a parameter dictionary
dict(a0=150, a1=25)
and passed it into the model as
model(x, **parameters)
which would make it easier to pass around all the parameters together if we needed them for other functions
#### Minimizing the Residuals
In this exercise, you will complete a function to visually compare model and data, and compute and print the RSS. You will call it more than once to see how RSS changes when you change values for
a0
and
a1
. We’ll see that the values for the parameters we found earlier are the ones needed to
minimize
the RSS.
# Complete function to load data, build model, compute RSS, and plot
def compute_rss_and_plot_fit(a0, a1):
xd, yd = load_data()
ym = model(xd, a0, a1)
residuals = ym - yd
rss = np.sum(np.square(yd - ym))
summary = "Parameters a0={}, a1={} yield RSS={:0.2f}".format(a0, a1, rss)
fig = plot_data_with_model(xd, yd, ym, summary)
return rss, summary
# Chose model parameter values and pass them into RSS function
rss, summary = compute_rss_and_plot_fit(a0=150, a1=25)
print(summary)
# Parameters a0=150, a1=25 yield RSS=14444.48

As stated earlier, the significance of RSS is in context of other values. More specifically, the minimum RSS is of value in identifying the specific set of parameter values for our model which yield the smallest residuals in an overall sense.
In this exercise you will compute and visualize how RSS varies for different values of model parameters. Start by holding the intercept constant, but vary the slope: and for each slope value, you’ll compute the model values, and the resulting RSS. Once you have an array of RSS values, you will determine minimal RSS value, in code, and from that minimum, determine the slope that resulted in that minimal RSS.
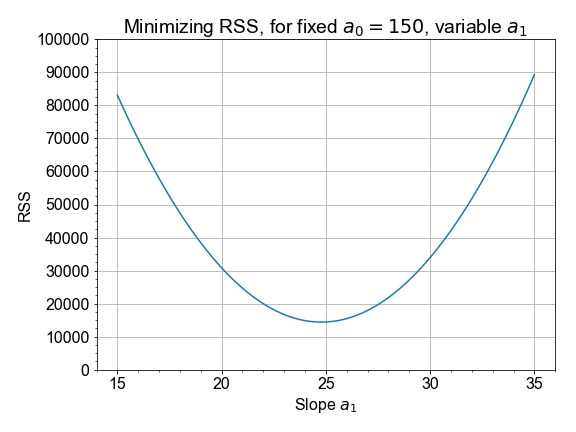
Use pre-loaded data arrays
x_data
,
y_data
, and empty container
rss_list
to get started.
# Loop over all trial values in a1_array, computing rss for each
a1_array = np.linspace(15, 35, 101)
for a1_trial in a1_array:
y_model = model(x_data, a0=150, a1=a1_trial)
rss_value = compute_rss(y_data, y_model)
rss_list.append(rss_value)
# Find the minimum RSS and the a1 value from whence it came
rss_array = np.array(rss_list)
best_rss = np.min(rss_array)
best_a1 = a1_array[np.where(rss_array==best_rss)]
print('The minimum RSS = {}, came from a1 = {}'.format(best_rss, best_a1))
# The minimum RSS = 14411.193019771845, came from a1 = [ 24.8]
# Plot your rss and a1 values to confirm answer
fig = plot_rss_vs_a1(a1_array, rss_array)

The best slope is the one out of an array of slopes than yielded the minimum RSS value out of an array of RSS values. Python tip: notice that we started with
rss_list
to make it easy to
.append()
but then later converted to
numpy.array()
to gain access to all the numpy methods.




####
Least-Squares with numpy
The formulae below are the result of working through the calculus discussed in the introduction. In this exercise, we’ll trust that the calculus correct, and implement these formulae in code.
# prepare the means and deviations of the two variables
x_mean = np.mean(x)
y_mean = np.mean(y)
x_dev = x - x_mean
y_dev = y - y_mean
# Complete least-squares formulae to find the optimal a0, a1
a1 = np.sum(x_dev * y_dev) / np.sum( np.square(x_dev) )
a0 = y_mean - (a1 * x_mean)
# Use the those optimal model parameters a0, a1 to build a model
y_model = model(x, a0, a1)
# plot to verify that the resulting y_model best fits the data y
fig, rss = compute_rss_and_plot_fit(a0, a1)

Notice that the optimal slope a1, according to least-squares, is a ratio of the covariance to the variance. Also, note that the values of the parameters obtained here are NOT exactly the ones used to generate the pre-loaded data (a1=25 and a0=150), but they are close to those. Least-squares does not guarantee zero error; there is no perfect solution, but in this case, least-squares is the best we can do.
#### Optimization with Scipy
It is possible to write a
numpy
implementation of the
analytic
solution to find the minimal RSS value. But for more complex models, finding analytic formulae is not possible, and so we turn to other methods.
In this exercise you will use
scipy.optimize
to employ a more general approach to solve the same optimization problem.
In so doing, you will see additional return values from the method that tell answer us “how good is best”. Here we will use the same measured data and parameters as seen in the last exercise for ease of comparison of the new
scipy
approach.
# Define a model function needed as input to scipy
def model_func(x, a0, a1):
return a0 + (a1*x)
# Load the measured data you want to model
x_data, y_data = load_data()
# call curve_fit, passing in the model function and data; then unpack the results
param_opt, param_cov = optimize.curve_fit(model_func, x_data, y_data)
a0 = param_opt[0] # a0 is the intercept in y = a0 + a1*x
a1 = param_opt[1] # a1 is the slope in y = a0 + a1*x
# test that these parameters result in a model that fits the data
fig, rss = compute_rss_and_plot_fit(a0, a1)
Notice that we passed the function object itself,
model_func
into
curve_fit
, rather than passing in the model data. The model function object was the input, because the optimization wants to know what form in general it’s solve for; had we passed in a model_func with more terms like an
a2*x**2
term, we would have seen different results for the parameters output
####
Least-Squares with statsmodels
Several python libraries provide convenient abstracted interfaces so that you need not always be so explicit in handling the machinery of optimization of the model.
As an example, in this exercise, you will use the
statsmodels
library in a more high-level, generalized work-flow for building a model using least-squares optimization (minimization of RSS).
To help get you started, we’ve pre-loaded the data from
x_data, y_data = load_data()
and stored it in a pandas DataFrame with column names
x_column
and
y_column
using
df = pd.DataFrame(dict(x_column=x_data, y_column=y_data))
# Pass data and `formula` into ols(), use and `.fit()` the model to the data
model_fit = ols(formula="y_column ~ x_column", data=df).fit()
# Use .predict(df) to get y_model values, then over-plot y_data with y_model
y_model = model_fit.predict(df)
fig = plot_data_with_model(x_data, y_data, y_model)
# Extract the a0, a1 values from model_fit.params
a0 = model_fit.params['Intercept']
a1 = model_fit.params['x_column']
# Visually verify that these parameters a0, a1 give the minimum RSS
fig, rss = compute_rss_and_plot_fit(a0, a1)
Note that the
params
container always uses ‘Intercept’ for the a0 key, but all higher order terms will have keys that match the column name from the pandas DataFrame that you passed into ols().
#### Linear Model in Anthropology
If you found part of a skeleton, from an adult human that lived thousands of years ago, how could you estimate the height of the person that it came from? This exercise is in part inspired by the work of forensic anthropologist Mildred Trotter, who built a regression model for the calculation of stature estimates from human “long bones” or femurs that is commonly used today.
In this exercise, you’ll use data from many living people, and the python library
scikit-learn
, to build a linear model relating the length of the femur (thigh bone) to the “stature” (overall height) of the person. Then, you’ll apply your model to make a prediction about the height of your ancient ancestor.
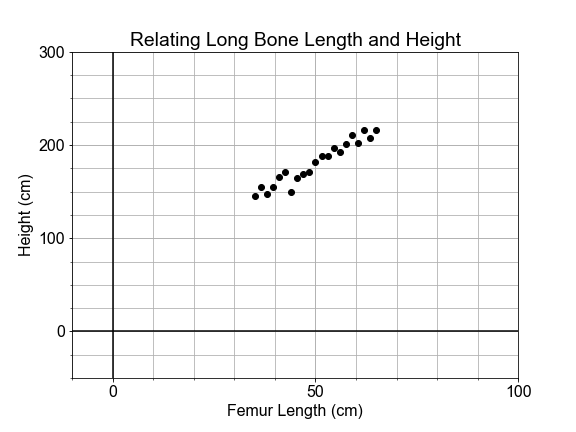
# import the sklearn class LinearRegression and initialize the model
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=False)
# Prepare the measured data arrays and fit the model to them
legs = legs.reshape(len(legs),1)
heights = heights.reshape(len(legs),1)
model.fit(legs, heights)
# Use the fitted model to make a prediction for the found femur
fossil_leg = 50.7
fossil_height = model.predict(fossil_leg)
print("Predicted fossil height = {:0.2f} cm".format(fossil_height[0,0]))
# Predicted fossil height = 181.34 cm
Notice that we used the pre-loaded data to fit or “train” the model, and then applied that model to make a prediction about newly collected data that was not part of the data used to fit the model. Also notice that
model.predict()
returns the answer as an array of
shape
=
(1,1)
, so we had to index into it with the
[0,0]
syntax when printing.
This is an artifact of our overly simplified use of
sklearn
here: the details of this are beyond the scope of the current course, but relate to the number of samples and features that one might use in a more sophisticated, generalized model.
#### Linear Model in Oceanography
Time-series data provides a context in which the “slope” of the linear model represents a “rate-of-change”.
In this exercise, you will use measurements of sea level change from 1970 to 2010, build a linear model of that changing sea level and use it to make a prediction about the future sea level rise.
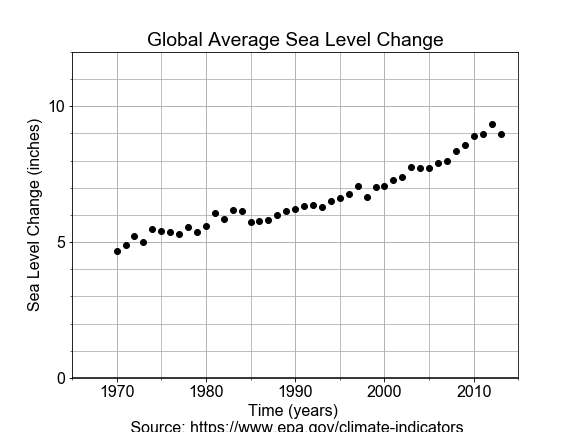
# Import LinearRegression class, build a model, fit to the data
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(years, levels)
# Use model to make a prediction for one year, 2100
future_year = 2100
future_level = model.predict(future_year)
print("Prediction: year = {}, level = {:.02f}".format(future_year, future_level[0,0]))
# Use model to predict for many years, and over-plot with measured data
years_forecast = np.linspace(1970, 2100, 131).reshape(-1, 1)
levels_forecast = model.predict(years_forecast)
fig = plot_data_and_forecast(years, levels, years_forecast, levels_forecast)

Note that with
scikit-learn
, although we could extract
a0 = model.intercept_[0]
and
a1 = model.coef_[0,0]
, we do not need to do that in order to make predictions, we just call
model.predict()
. With more complex models, these parameters may not have easy physical interpretations.
Notice also that although our model is linear, the actual data appears to have an up-turn that might be better modeled by adding a quadratic or even exponential term to our model. The linear model forecast may be underestimating the rate of increase in sea level.
#### Linear Model in Cosmology
Less than 100 years ago, the universe appeared to be composed of a single static galaxy, containing perhaps a million stars. Today we have observations of hundreds of billions of galaxies, each with hundreds of billions of stars, all moving.
The beginnings of the modern physical science of cosmology came with the publication in 1929 by Edwin Hubble that included use of a linear model.
In this exercise, you will build a model whose slope will give Hubble’s Constant, which describes the velocity of galaxies as a linear function of distance from Earth.

# Fit the model, based on the form of the formula
model_fit = ols(formula="velocities ~ distances", data=df).fit()
# Extract the model parameters and associated "errors" or uncertainties
a0 = model_fit.params['Intercept']
a1 = model_fit.params['distances']
e0 = model_fit.bse['Intercept']
e1 = model_fit.bse['distances']
# Print the results
print('For slope a1={:.02f}, the uncertainty in a1 is {:.02f}'.format(a1, e1))
print('For intercept a0={:.02f}, the uncertainty in a0 is {:.02f}'.format(a0, e0))
# For slope a1=454.16, the uncertainty in a1 is 75.24
# For intercept a0=-40.78, the uncertainty in a0 is 83.44
Later in the course, we will spend more time with model uncertainty, and exploring how to compute it ourselves. Notice the
~
in the
formula
means “similar to” and is interpreted by
statsmodels
to mean that
y ~ x
have a linear relationship.
More recently, observed astrophysical data extend the veritical scale of measured data out further by almost a factor of 50. Using this new data to model gives a very different value for the slope, Hubble’s Constant, of about 72. Modeling with new data revealed a different slope, and this has big implications in the physics of the Universe.

#### Interpolation: Inbetween Times
In this exercise, you will build a linear model by fitting monthly time-series data for the Dow Jones Industrial Average (DJIA) and then use that model to make predictions for daily data (in effect, an interpolation). Then you will compare that daily prediction to the real daily DJIA data.
A few notes on the data. “OHLC” stands for “Open-High-Low-Close”, which is usually daily data, for example the opening and closing prices, and the highest and lowest prices, for a stock in a given day. “DayCount” is an integer number of days from start of the data collection.
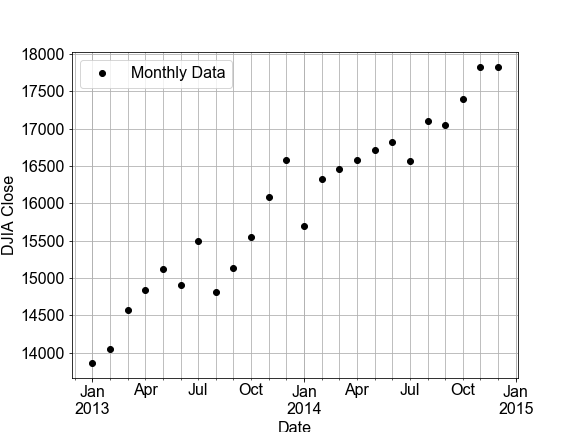
df_monthly.head(3)
Open High Low Close \
Date
2013-01-01 13104.299805 13969.990234 13104.299805 13860.580078
2013-02-01 13860.580078 14149.150391 13784.009766 14054.490234
2013-03-01 14054.490234 14585.099609 13937.599609 14578.540039
Adj Close Volume Jday DayCount
Date
2013-01-01 13860.580078 2786680000 2456293.5 1827.0
2013-02-01 14054.490234 2487580000 2456324.5 1858.0
2013-03-01 14578.540039 2546320000 2456352.5 1886.0
df_daily.head(3)
Open High Low Close \
Date
2013-01-02 13104.299805 13412.709961 13104.299805 13412.549805
2013-01-03 13413.009766 13430.599609 13358.299805 13391.360352
2013-01-04 13391.049805 13447.110352 13376.230469 13435.209961
Adj Close Volume Jday DayCount
Date
2013-01-02 13412.549805 161430000 2456294.5 1827.0
2013-01-03 13391.360352 129630000 2456295.5 1828.0
2013-01-04 13435.209961 107590000 2456296.5 1829.0
# build and fit a model to the df_monthly data
model_fit = ols('Close ~ DayCount', data=df_monthly).fit()
# Use the model FIT to the MONTHLY data to make a predictions for both monthly and daily data
df_monthly['Model'] = model_fit.predict(df_monthly.DayCount)
df_daily['Model'] = model_fit.predict(df_daily.DayCount)
# Plot the monthly and daily data and model, compare the RSS values seen on the figures
fig_monthly = plot_model_with_data(df_monthly)
fig_daily = plot_model_with_data(df_daily)


Notice the monthly data looked linear, but the daily data clearly has additional, nonlinear trends. Under-sampled data often misses real-world features in the data on smaller time or spatial scales. Using the model from the under-sampled data to make interpolations to the daily data can result is large residuals. Notice that the RSS value for the daily plot is more than 30 times worse than the monthly plot
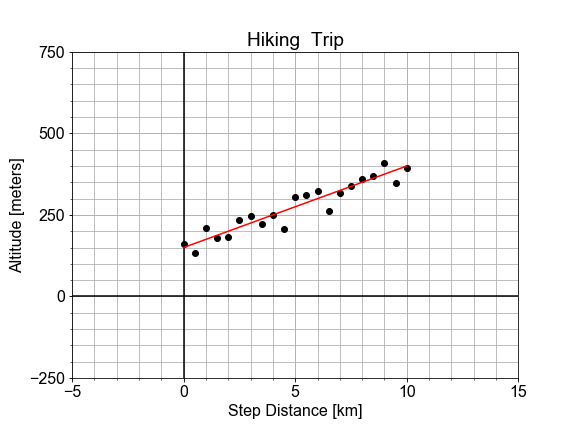
#### Extrapolation: Going Over the Edge
In this exercise, we consider the perils of extrapolation. Shown here is the profile of a hiking trail on a mountain. One portion of the trail, marked in black, looks linear, and was used to build a model. But we see that the best fit line, shown in red, does not fit outside the original “domain”, as it extends into this new outside data, marked in blue.
If we want use the model to make predictions for the altitude, but still be accurate to within some tolerance, what are the smallest and largest values of independent variable
x
that we can allow ourselves to apply the model to?”
Here, use the preloaded
x_data
,
y_data
,
y_model
, and
plot_data_model_tolerance()
to complete your solution.
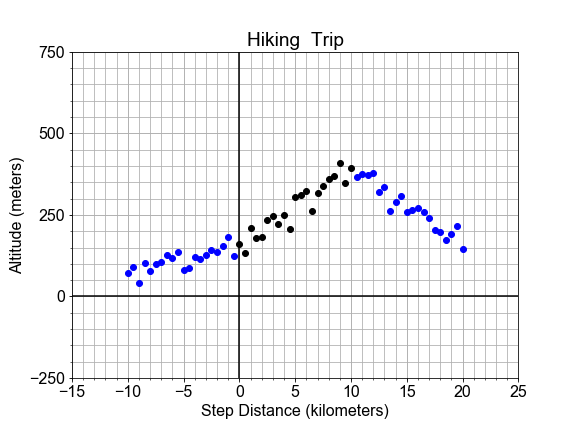
# Compute the residuals, "data - model", and determine where [residuals < tolerance]
residuals = np.abs(y_data - y_model)
tolerance = 100
x_good = x_data[residuals < tolerance]
# Find the min and max of the "good" values, and plot y_data, y_model, and the tolerance range
print('Minimum good x value = {}'.format(np.min(x_good)))
print('Maximum good x value = {}'.format(np.max(x_good)))
fig = plot_data_model_tolerance(x_data, y_data, y_model, tolerance)

Notice the range of good values, which extends a little out into the new data, is marked in green on the plot. By comparing the residuals to a tolerance threshold, we can quantify how far out out extrapolation can go before the difference between model and data gets too large.








#### RMSE Step-by-step
In this exercise, you will quantify the over-all model “goodness-of-fit” of a pre-built model, by computing one of the most common quantitative measures of model quality, the RMSE, step-by-step.
Start with the pre-loaded data
x_data
and
y_data
, and use it with a predefined modeling function
model_fit_and_predict()
.
# Build the model and compute the residuals "model - data"
y_model = model_fit_and_predict(x_data, y_data)
residuals = y_data - y_model
# Compute the RSS, MSE, and RMSE and print the results
RSS = np.sum(np.square(residuals))
MSE = RSS/len(residuals)
RMSE = np.sqrt(MSE)
print('RMSE = {:0.2f}, MSE = {:0.2f}, RSS = {:0.2f}'.format(RMSE, MSE, RSS))
# RMSE = 26.23, MSE = 687.83, RSS = 14444.48
Notice that instead of computing
RSS
and normalizing with division by
len(residuals)
to get the MSE, you could have just applied
np.mean(np.square())
to the
residuals
.
Another useful point to help you remember; you can think of the MSE like a variance, but instead of differencing the data from its mean, you difference the data and the model. Similarly, think of RMSE as a standard deviation.
#### R-Squared
In this exercise you’ll compute another measure of goodness, R-squared . R-squared is the ratio of the variance of the residuals divided by the variance of the data we are modeling, and in so doing, is a measure of how much of the variance in your data is “explained” by your model, as expressed in the spread of the residuals.
Here we have pre-loaded the data
x_data
,
y_data
and the model predictions
y_model
for the best fit model; you’re goal is to compute the R-squared measure to quantify how much this linear model accounts for variation in the data.
# Compute the residuals and the deviations
residuals = y_model - y_data
deviations = np.mean(y_data) - y_data
# Compute the variance of the residuals and deviations
var_residuals = np.sum(np.square(residuals))
var_deviations = np.sum(np.square(deviations))
# Compute r_squared as 1 - the ratio of RSS/Variance
r_squared = 1 - (var_residuals / var_deviations)
print('R-squared is {:0.2f}'.format(r_squared))
# R-squared is 0.89
Notice that R-squared varies from 0 to 1, where a value of 1 means that the model and the data are perfectly correlated and all variation in the data is predicted by the model. A value of zero would mean none of the variation in the data is predicted by the model. Here, the data points are close to the line, so R-squared is closer to 1.0




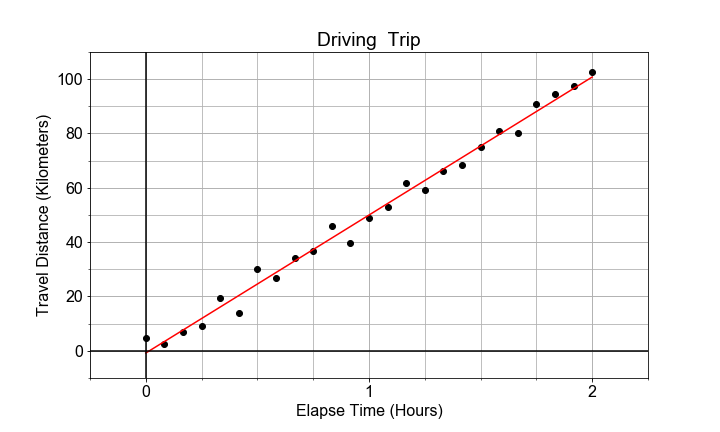
#### Variation Around the Trend
The data need not be perfectly linear, and there may be some random variation or “spread” in the measurements, and that does translate into variation of the model parameters. This variation is in the parameter is quantified by “standard error”, and interpreted as “uncertainty” in the estimate of the model parameter.
In this exercise, you will use
ols
from
statsmodels
to build a model and extract the standard error for each parameter of that model.
# Store x_data and y_data, as times and distances, in df, and use ols() to fit a model to it.
df = pd.DataFrame(dict(times=x_data, distances=y_data))
model_fit = ols(formula="distances ~ times", data=df).fit()
# Extact the model parameters and their uncertainties
a0 = model_fit.params['Intercept']
e0 = model_fit.bse['Intercept']
a1 = model_fit.params['times']
e1 = model_fit.bse['times']
# Print the results with more meaningful names
print('Estimate of the intercept = {:0.2f}'.format(a0))
print('Uncertainty of the intercept = {:0.2f}'.format(e0))
print('Estimate of the slope = {:0.2f}'.format(a1))
print('Uncertainty of the slope = {:0.2f}'.format(e1))
# Estimate of the intercept = -0.81
# Uncertainty of the intercept = 1.29
# Estimate of the slope = 50.78
# Uncertainty of the slope = 1.11
The size of the parameters standard error only makes sense in comparison to the parameter value itself. In fact the units are the same! So a1 and e1 both have units of velocity (meters/second), and a0 and e0 both have units of distance (meters).
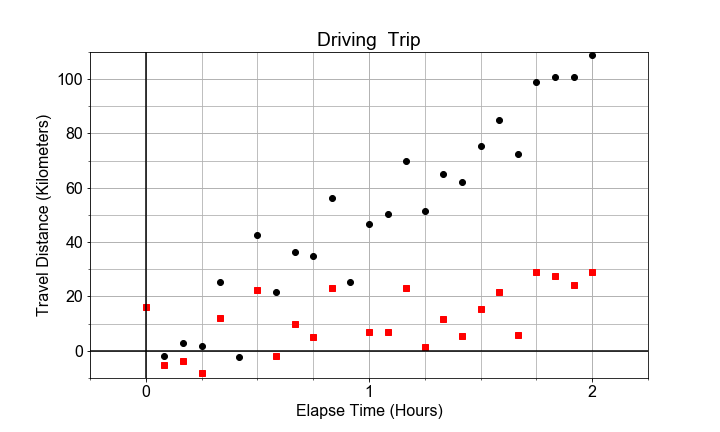
#### Variation in Two Parts
Given two data sets of distance-versus-time data, one with very small velocity and one with large velocity. Notice that both may have the same standard error of slope, but different R-squared for the model overall, depending on the size of the slope (“effect size”) as compared to the standard error (“uncertainty”).
If we plot both data sets as scatter plots on the same axes, the contrast is clear. Variation due to the slope is different than variation due to the random scatter about the trend line. In this exercise, your goal is to compute the standard error and R-squared for two data sets and compare.
# Build and fit two models, for columns distances1 and distances2 in df
model_1 = ols(formula="distances1 ~ times", data=df).fit()
model_2 = ols(formula="distances2 ~ times", data=df).fit()
# Extract R-squared for each model, and the standard error for each slope
se_1 = model_1.bse['times']
se_2 = model_2.bse['times']
rsquared_1 = model_1.rsquared
rsquared_2 = model_2.rsquared
# Print the results
print('Model 1: SE = {:0.3f}, R-squared = {:0.3f}'.format(se_1, rsquared_1))
print('Model 2: SE = {:0.3f}, R-squared = {:0.3f}'.format(se_2, rsquared_2))
# Model 1: SE = 3.694, R-squared = 0.898
# Model 2: SE = 3.694, R-squared = 0.335
Notice that the standard error is the same for both models, but the r-squared changes. The uncertainty in the estimates of the model parameters is indepedent from R-squred because that uncertainty is being driven not by the linear trend, but by the inherent randomness in the data. This serves as a transition into looking at statistical inference in linear models.
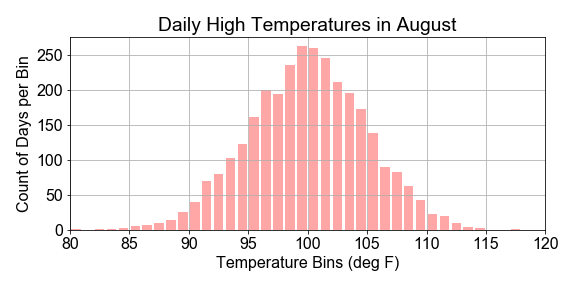
#### Sample Statistics versus Population
In this exercise you will work with a preloaded
population
. You will construct a
sample
by drawing points at random from the population. You will compute the mean standard deviation of the sample taken from that population to test whether the sample is representative of the population. Your goal is to see where the sample statistics are the same or very close to the population statistics.
# Compute the population statistics
print("Population mean {:.1f}, stdev {:.2f}".format( population.mean(), population.std() ))
# Set random seed for reproducibility
np.random.seed(42)
# Construct a sample by randomly sampling 31 points from the population
sample = np.random.choice(population, size=31)
# Compare sample statistics to the population statistics
print(" Sample mean {:.1f}, stdev {:.2f}".format( sample.mean(), sample.std() ))
# Population mean 100.0, stdev 9.74
# Sample mean 102.1, stdev 9.34
Notice that the sample statistics are similar to the population statistics, but not the identical. If you were to compute the
len()
of each array, it is very different, but the means are not that much different as you might expect.
#### Variation in Sample Statistics
If we create one sample of
size=1000
by drawing that many points from a population. Then compute a sample statistic, such as the mean, a single value that summarizes the sample itself.
If you repeat that sampling process
num_samples=100
times, you get
100
samples. Computing the sample statistic, like the mean, for each of the different samples, will result in a distribution of values of the mean. The goal then is to compute the mean of the means and standard deviation of the means.
Here you will use the preloaded
population
,
num_samples
, and
num_pts
, and note that the
means
and
deviations
arrays have been initialized to zero to give you containers to use for the for loop.
# Initialize two arrays of zeros to be used as containers
means = np.zeros(num_samples)
stdevs = np.zeros(num_samples)
# For each iteration, compute and store the sample mean and sample stdev
for ns in range(num_samples):
sample = np.random.choice(population, num_pts)
means[ns] = sample.mean()
stdevs[ns] = sample.std()
# Compute and print the mean() and std() for the sample statistic distributions
print("Means: center={:>6.2f}, spread={:>6.2f}".format(means.mean(), means.std()))
print("Stdevs: center={:>6.2f}, spread={:>6.2f}".format(stdevs.mean(), stdevs.std()))
# Means: center=100.00, spread= 0.33
# Stdevs: center= 10.01, spread= 0.22
If we only took one sample, instead of 100, there could be only a single mean and the standard deviation of that single value is zero. But each sample is different because of the randomness of the draws. The mean of the means is our estimate for the population mean, the stdev of the means is our measure of the uncertainty in our estimate of the population mean. This is the same concept as the standard error of the slope seen in linear regression.
#### Visualizing Variation of a Statistic
Previously, you have computed the variation of sample statistics. Now you’ll visualize that variation.
We’ll start with a preloaded
population
and a predefined function
get_sample_statistics()
to draw the samples, and return the sample statistics arrays.
Here we will use a predefined
plot_hist()
function that wraps the
matplotlib
method
axis.hist()
, which both bins and plots the array passed in. In this way you can see how the sample statistics have a distribution of values, not just a single value.
# Generate sample distribution and associated statistics
means, stdevs = get_sample_statistics(population, num_samples=100, num_pts=1000)
# Define the binning for the histograms
mean_bins = np.linspace(97.5, 102.5, 51)
std_bins = np.linspace(7.5, 12.5, 51)
# Plot the distribution of means, and the distribution of stdevs
fig = plot_hist(data=means, bins=mean_bins, data_name="Means", color='green')
fig = plot_hist(data=stdevs, bins=std_bins, data_name="Stdevs", color='red')





What is the probability that A occurs given B that occured
Given the model, what is the probability that the model outputs any particular data point
Given the data, what is the likelihood that a candidate model could output the particular data point




#### Estimation of Population Parameters
Imagine a constellation (“population”) of satellites orbiting for a full year, and the distance traveled in each hour is measured in kilometers. There is variation in the distances measured from hour-to-hour, due to unknown complications of orbital dynamics. Assume we cannot measure all the data for the year, but we wish to build a population model for the variations in orbital distance per hour (speed) based on a sample of measurements.
In this exercise, you will assume that the population of hourly distances are best modeled by a gaussian, and further assume that the parameters of that population model can be estimated from the sample statistics. Start with the preloaded
sample_distances
that was taken from a population of cars.
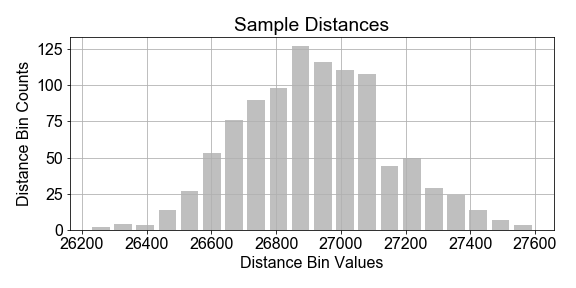
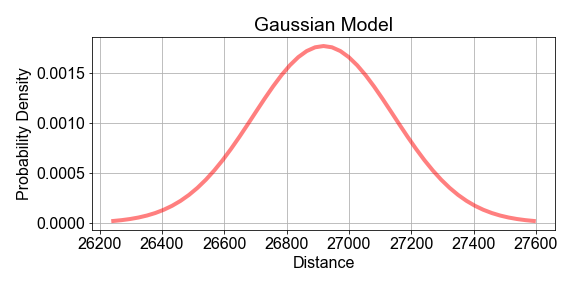
# Compute the mean and standard deviation of the sample_distances
sample_mean = np.mean(sample_distances)
sample_stdev = np.std(sample_distances)
# Use the sample mean and stdev as estimates of the population model parameters mu and sigma
population_model = gaussian_model(sample_distances, mu=sample_mean, sigma=sample_stdev)
# Plot the model and data to see how they compare
fig = plot_data_and_model(sample_distances, population_model)

Notice in the plot that the data and the model do not line up exactly. This is to be expected because the sample is just a subset of the population, and any model built from it cannot be a prefect representation of the population. Also notice the vertical axis: it shows the normalize data bin counts, and the probability density of the model. Think of that as probability-per-bin, so that if summed all the bins, the total would be 1.0.
#### Maximizing Likelihood, Part 1
Previously, we chose the sample
mean
as an estimate of the population model paramter
mu
. But how do we know that the sample mean is the best estimator? This is tricky, so let’s do it in two parts.
In Part 1, you will use a computational approach to compute the log-likelihood of a given estimate. Then, in Part 2, we will see that when you compute the log-likelihood for many possible guess values of the estimate, one guess will result in the maximum likelihood.
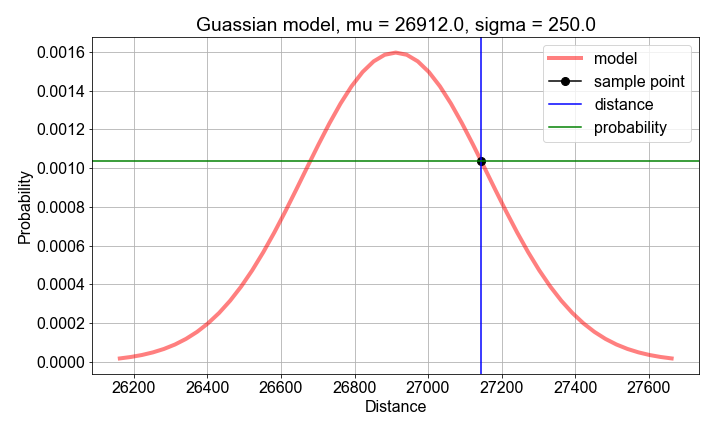
# Compute sample mean and stdev, for use as model parameter value guesses
mu_guess = np.mean(sample_distances)
sigma_guess = np.std(sample_distances)
# For each sample distance, compute the probability modeled by the parameter guesses
probs = np.zeros(len(sample_distances))
for n, distance in enumerate(sample_distances):
probs[n] = gaussian_model(distance, mu=mu_guess, sigma=sigma_guess)
# Compute and print the log-likelihood as the sum() of the log() of the probabilities
loglikelihood = np.sum(np.log(probs))
print('For guesses mu={:0.2f} and sigma={:0.2f}, the loglikelihood={:0.2f}'.format(mu_guess, sigma_guess, loglikelihood))
# For guesses mu=26918.10 and sigma=224.88, the loglikelihood=-6834.53
Although the likelihood (the product of the probabilities) is easier to interpret, the loglikelihood has better numerical properties. Products of small and large numbers can cause numerical artifacts, but sum of the logs usually doesnt suffer those same artifacts, and the “sum(log(things))” is closely related to the “product(things)”
#### Maximizing Likelihood, Part 2
In Part 1, you computed a single log-likelihood for a single
mu
. In this Part 2, you will apply the predefined function
compute_loglikelihood()
to compute an
array
of log-likelihood values, one for each element in an
array
of possible
mu
values.
The goal then is to determine which single
mu
guess leads to the single
maximum
value of the loglikelihood array.
To get started, use the preloaded data
sample_distances
,
sample_mean
,
sample_stdev
and a helper function
compute_loglikelihood()
.
# Create an array of mu guesses, centered on sample_mean, spread out +/- by sample_stdev
low_guess = sample_mean - 2*sample_stdev
high_guess = sample_mean + 2*sample_stdev
mu_guesses = np.linspace(low_guess, high_guess, 101)
# Compute the loglikelihood for each model created from each guess value
loglikelihoods = np.zeros(len(mu_guesses))
for n, mu_guess in enumerate(mu_guesses):
loglikelihoods[n] = compute_loglikelihood(sample_distances, mu=mu_guess, sigma=sample_stdev)
# Find the best guess by using logical indexing, the print and plot the result
best_mu = mu_guesses[loglikelihoods==np.max(loglikelihoods)]
print('Maximum loglikelihood found for best mu guess={}'.format(best_mu))
fig = plot_loglikelihoods(mu_guesses, loglikelihoods)
# Maximum loglikelihood found for best mu guess=[ 26918.39241406]
Notice that the guess for mu that gave the maximum likelihood is precisely the same value as the
sample.mean()
. The
sample_mean
is thus said to be the “Maximum Likelihood Estimator” of the population mean
mu
. We call that value of
mu
the “Maximum Likelihood Estimator” of the population
mu
because, of all the
mu
values tested, it results in a model population with the greatest likelihood of producing the sample data we have.

#### Bootstrap and Standard Error
Imagine a National Park where park rangers hike each day as part of maintaining the park trails. They don’t always take the same path, but they do record their final distance and time. We’d like to build a statistical model of the variations in daily distance traveled from a limited sample of data from one ranger.
Your goal is to use bootstrap resampling, computing one mean for each resample, to create a distribution of means, and then compute standard error as a way to quantify the “uncertainty” in the sample statistic as an estimator for the population statistic .
Use the preloaded
sample_data
array of 500 independent measurements of distance traveled. For now, we this is a simulated data set to simplify this lesson. Later, we’ll see more realistic data.
# Use the sample_data as a model for the population
population_model = sample_data
# Resample the population_model 100 times, computing the mean each sample
for nr in range(num_resamples):
bootstrap_sample = np.random.choice(population_model, size=resample_size, replace=True)
bootstrap_means[nr] = np.mean(bootstrap_sample)
# Compute and print the mean, stdev of the resample distribution of means
distribution_mean = np.mean(bootstrap_means)
standard_error = np.std(bootstrap_means)
print('Bootstrap Distribution: center={:0.1f}, spread={:0.1f}'.format(distribution_mean, standard_error))
# Plot the bootstrap resample distribution of means
fig = plot_data_hist(bootstrap_means)

Notice that
standard_error
is just one measure of spread of the distribution of bootstrap resample means. You could have computed the
confidence_interval
using
np.percentile(bootstrap_means, 0.95)
and
np.percentile(bootstrap_means, 0.05)
to find the range distance values containing the inner 90% of the distribution of means.
#### Estimating Speed and Confidence
Let’s continue looking at the National Park hiking data. Notice that some distances are negative because they walked in the opposite direction from the trail head; the data are messy so let’s just focus on the overall trend.
In this exercise, you goal is to use boot-strap resampling to find the distribution of speed values for a linear model, and then from that distribution, compute the best estimate for the speed and the 90th percent confidence interval of that estimate. The speed here is the slope parameter from the linear regression model to fit distance as a function of time.
To get you started, we’ve preloaded
distance
and
time
data, together with a pre-defined
least_squares()
function to compute the speed value for each resample.
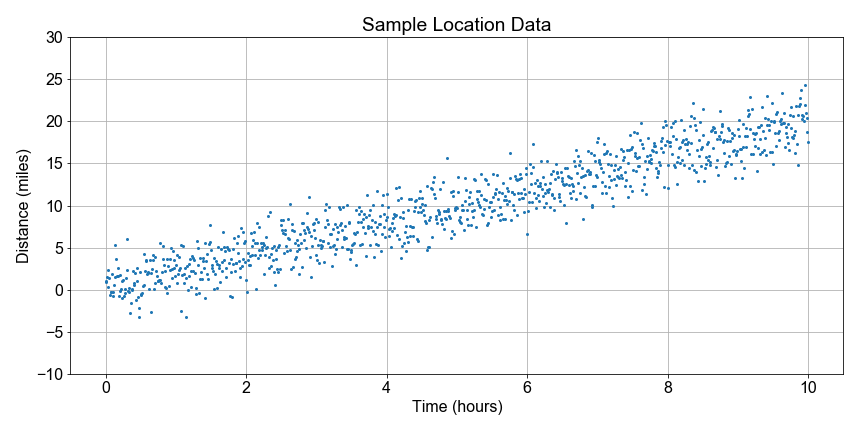
# Resample each preloaded population, and compute speed distribution
population_inds = np.arange(0, 99, dtype=int)
for nr in range(num_resamples):
sample_inds = np.random.choice(population_inds, size=100, replace=True)
sample_inds.sort()
sample_distances = distances[sample_inds]
sample_times = times[sample_inds]
a0, a1 = least_squares(sample_times, sample_distances)
resample_speeds[nr] = a1
# Compute effect size and confidence interval, and print
speed_estimate = np.mean(resample_speeds)
ci_90 = np.percentile(resample_speeds, [5, 95])
print('Speed Estimate = {:0.2f}, 90% Confidence Interval: {:0.2f}, {:0.2f} '.format(speed_estimate, ci_90[0], ci_90[1]))
# Speed Estimate = 2.29, 90% Confidence Interval: 1.23, 3.35
Notice that the speed estimate (the mean) falls inside the confidence interval (the 5th and 95th percentiles). Moreover, notice if you computed the standard error, it would also fit inside the confidence interval. Think of the standard error here as the ‘one sigma’ confidence interval. Note that this should be very similar to the summary output of a statsmodels ols() linear regression model, but here you can compute arbitrary percentiles because you have the entire speeds distribution.
#### Visualize the Bootstrap
Continuing where we left off earlier in this lesson, let’s visualize the bootstrap distribution of speeds estimated using bootstrap resampling, where we computed a least-squares fit to the slope for every sample to test the variation or uncertainty in our slope estimation.
To get you started, we’ve preloaded a function
compute_resample_speeds(distances, times)
to do the computation of generate the speed sample distribution.
# Create the bootstrap distribution of speeds
resample_speeds = compute_resample_speeds(distances, times)
speed_estimate = np.mean(resample_speeds)
percentiles = np.percentile(resample_speeds, [5, 95])
# Plot the histogram with the estimate and confidence interval
fig, axis = plt.subplots()
hist_bin_edges = np.linspace(0.0, 4.0, 21)
axis.hist(resample_speeds, bins=hist_bin_edges, color='green', alpha=0.35, rwidth=0.8)
axis.axvline(speed_estimate, label='Estimate', color='black')
axis.axvline(percentiles[0], label=' 5th', color='blue')
axis.axvline(percentiles[1], label='95th', color='blue')
axis.legend()
plt.show()

Notice that vertical lines marking the 5th (left) and 95th (right) percentiles mark the extent of the confidence interval, while the speed estimate (center line) is the mean of the distribution and falls between them. Note the speed estimate is the mean, not the median, which would be 50% percentile.


#### Test Statistics and Effect Size
How can we explore linear relationships with bootstrap resampling? Back to the trail! For each hike plotted as one point, we can see that there is a linear relationship between total distance traveled and time elapsed. It we treat the distance traveled as an “effect” of time elapsed, then we can explore the underlying connection between linear regression and statistical inference.
In this exercise, you will separate the data into two populations, or “categories”: early times and late times. Then you will look at the differences between the total distance traveled within each population. This difference will serve as a “test statistic”, and it’s distribution will test the effect of separating distances by times.

# Create two poulations, sample_distances for early and late sample_times.
# Then resample with replacement, taking 500 random draws from each population.
group_duration_short = sample_distances[sample_times < 5]
group_duration_long = sample_distances[sample_times > 5]
resample_short = np.random.choice(group_duration_short, size=500, replace=True)
resample_long = np.random.choice(group_duration_long, size=500, replace=True)
# Difference the resamples to compute a test statistic distribution, then compute its mean and stdev
test_statistic = resample_long - resample_short
effect_size = np.mean(test_statistic)
standard_error = np.std(test_statistic)
# Print and plot the results
print('Test Statistic: mean={:0.2f}, stdev={:0.2f}'.format(effect_size, standard_error))
fig = plot_test_statistic(test_statistic)
# Test Statistic: mean=10.01, stdev=4.62

Notice again, the test statistic is the difference between a distance drawn from short duration trips and one drawn from long duration trips. The distribution of difference values is built up from differencing each point in the early time range with one from the late time range. The mean of the test statistic is not zero and tells us that there is on average a difference in distance traveled when comparing short and long duration trips. Again, we call this the ‘effect size’. The time increase had an effect on distance traveled. The standard error of the test statistic distribution is not zero, so there is some spread in that distribution, or put another way, uncertainty in the size of the effect.
#### Null Hypothesis
In this exercise, we formulate the null hypothesis as
short and long time durations have no effect on total distance traveled.
We interpret the “zero effect size” to mean that if we shuffled samples between short and long times, so that two new samples each have a mix of short and long duration trips, and then compute the test statistic, on average it will be zero.
In this exercise, your goal is to perform the shuffling and resampling. Start with the predefined
group_duration_short
and
group_duration_long
which are the un-shuffled time duration groups.
# Shuffle the time-ordered distances, then slice the result into two populations.
shuffle_bucket = np.concatenate((group_duration_short, group_duration_long))
np.random.shuffle(shuffle_bucket)
slice_index = len(shuffle_bucket)//2
shuffled_half1 = shuffle_bucket[0:slice_index]
shuffled_half2 = shuffle_bucket[slice_index:]
# Create new samples from each shuffled population, and compute the test statistic
resample_half1 = np.random.choice(shuffled_half1, size=500, replace=True)
resample_half2 = np.random.choice(shuffled_half2, size=500, replace=True)
test_statistic = resample_half2 - resample_half1
# Compute and print the effect size
effect_size = np.mean(test_statistic)
print('Test Statistic, after shuffling, mean = {}'.format(effect_size))
# Test Statistic, after shuffling, mean = 0.09300205283002799
Notice that your effect size is not exactly zero because there is noise in the data. But the effect size is much closer to zero than before shuffling. Notice that if you rerun your code, which will generate a new shuffle, you will get slightly different results each time for the effect size, but np.abs(test_statistic) should be less than about 1.0, due to the noise, as opposed to the slope, which was about 2.0
#### Visualizing Test Statistics
In this exercise, you will approach the null hypothesis by comparing the distribution of a test statistic arrived at from two different ways.
First, you will examine two “populations”, grouped by early and late times, and computing the test statistic distribution. Second, shuffle the two populations, so the data is no longer time ordered, and each has a mix of early and late times, and then recompute the test statistic distribution.
To get you started, we’ve pre-loaded the two time duration groups,
group_duration_short
and
group_duration_long
, and two functions,
shuffle_and_split()
and
plot_test_statistic()
.
# From the unshuffled groups, compute the test statistic distribution
resample_short = np.random.choice(group_duration_short, size=500, replace=True)
resample_long = np.random.choice(group_duration_long, size=500, replace=True)
test_statistic_unshuffled = resample_long - resample_short
# Shuffle two populations, cut in half, and recompute the test statistic
shuffled_half1, shuffled_half2 = shuffle_and_split(group_duration_short, group_duration_long)
resample_half1 = np.random.choice(shuffled_half1, size=500, replace=True)
resample_half2 = np.random.choice(shuffled_half2, size=500, replace=True)
test_statistic_shuffled = resample_half2 - resample_half1
# Plot both the unshuffled and shuffled results and compare
fig = plot_test_statistic(test_statistic_unshuffled, label='Unshuffled')
fig = plot_test_statistic(test_statistic_shuffled, label='Shuffled')


Notice that after you shuffle, the effect size went almost to zero and the spread increased, as measured by the standard deviation of the sample statistic, aka the ‘standard error’. So shuffling did indeed have an effect. The null hypothesis is disproven. Time ordering does in fact have a non-zero effect on distance traveled. Distance is correlated to time.
#### Visualizing the P-Value
In this exercise, you will visualize the p-value, the chance that the effect (or “speed”) we estimated, was the result of random variation in the sample. Your goal is to visualize this as the fraction of points in the shuffled test statistic distribution that fall to the right of the mean of the test statistic (“effect size”) computed from the unshuffled samples.
To get you started, we’ve preloaded the
group_duration_short
and
group_duration_long
and functions
compute_test_statistic()
,
shuffle_and_split()
, and
plot_test_statistic_effect()
# Compute the test stat distribution and effect size for two population groups
test_statistic_unshuffled = compute_test_statistic(group_duration_short, group_duration_long)
effect_size = np.mean(test_statistic_unshuffled)
# Randomize the two populations, and recompute the test stat distribution
shuffled_half1, shuffled_half2 = shuffle_and_split(group_duration_short, group_duration_long)
test_statistic_shuffled = compute_test_statistic(shuffled_half1, shuffled_half2)
# Compute the p-value as the proportion of shuffled test stat values >= the effect size
condition = test_statistic_shuffled >= effect_size
p_value = len(test_statistic_shuffled[condition]) / len(test_statistic_shuffled)
# Print p-value and overplot the shuffled and unshuffled test statistic distributions
print("The p-value is = {}".format(p_value))
fig = plot_test_stats_and_pvalue(test_statistic_unshuffled, test_statistic_shuffled)
# The p-value is = 0.126

Note that the entire point of this is compute a p-value to quantify the chance that our estimate for speed could have been obtained by random chance. On the plot, the unshuffle test stats are the distribution of speed values estimated from time-ordered distances. The shuffled test stats are the distribution of speed values computed from randomizing unordered distances. Values of the shuffled stats to the right of the mean non-shuffled effect size line are those that both (1) could have both occured randomly and (2) are at least as big as the estimate you want to use for speed.
Thank you for reading and hope you’ve learned a lot.